Early Fire Detection
Highlights


Results
Details
Patch-based fire detection system combining classical vision and deep learning for fast, robust early-stage fire localization on edge devices.
Problem
Early-stage fire detection in wide-area surveillance footage is challenging due to small flame regions, off-center appearance, and strict latency constraints on edge devices. While object detection models can localize fire directly, they are often too heavy, data-hungry, and difficult to deploy in real-time monitoring systems.
This project explores an alternative design: high-speed fire classification + spatial reasoning, rather than full-frame detection.
Project Structure
The work progressed through five structured phases:
- Phase 0 — Data preparation and system design
- Phase 1 — Initial patch-based fire classification experiments
- Phase 2 — Detailed evaluation and comparison with detection models
- Phase 3 — Training strategy and robustness analysis
Each phase incrementally addressed a concrete limitation observed in the previous stage.
Phase 0 — Data Preparation
To overcome limited annotated fire datasets, data was aggregated from multiple public sources, including MIVIA, FireNet, SKLFS, and Roboflow fire datasets.
Instead of training on full images:
- Images were divided into fixed-size patches
- Patches were labeled as fire / non-fire based on overlap with ground-truth regions
- Balanced sampling ensured equal representation of fire and non-fire patches
This design simplified training while enabling dense spatial coverage.
Phase 1 — Initial Fire Classification
A lightweight CNN-based binary fire classifier was trained on image patches.
Advantages of this approach:
- Small model size
- Fast inference
- Simple annotation pipeline
- Suitable for edge deployment
However, early experiments revealed a key limitation:
Fire patches not centered within the window receive significantly lower confidence scores.
Phase 2 — Detailed Analysis and Limitations
Further evaluation showed that:
- Sliding-window classification is computationally expensive
- Fixed grid partitioning reduces computation but introduces off-center bias
- Flames near patch boundaries are frequently misclassified
Comparisons with YOLO-based detectors confirmed:
- Detection models are robust but costly
- Classification models are efficient but spatially sensitive
This led to a critical insight:
Spatial alignment matters more than model capacity for early-stage fire detection.
Phase 3 — Fire Centering and Training Strategy
To address off-center degradation, a fire centering and expansion strategy was introduced.
GMM-based Fire Masking
- A Gaussian Mixture Model (GMM) was trained on fire pixel color distributions
- Fire likelihood maps were generated via probabilistic inference
- Binary fire masks were obtained using thresholding and morphological filtering
Fire Centering
Using the estimated fire mask:
- The centroid of the fire region was computed
- Image patches were spatially transformed via folding and mirroring
- Fire regions were moved toward the patch center and enlarged
This preprocessing step significantly improved classification confidence without increasing model complexity.
Phase 4 — Full Algorithm and Inference Pipeline
The final system integrates classical vision and deep learning into a unified pipeline:
- Divide input frames into grid-based patches
- Apply GMM-based fire likelihood estimation
- Perform fire centering and expansion if likelihood exceeds a threshold
- Classify centered patches using the trained fire classifier
- Aggregate patch-level predictions into a spatial fire map
- Trigger alarms based on spatial density and temporal persistence
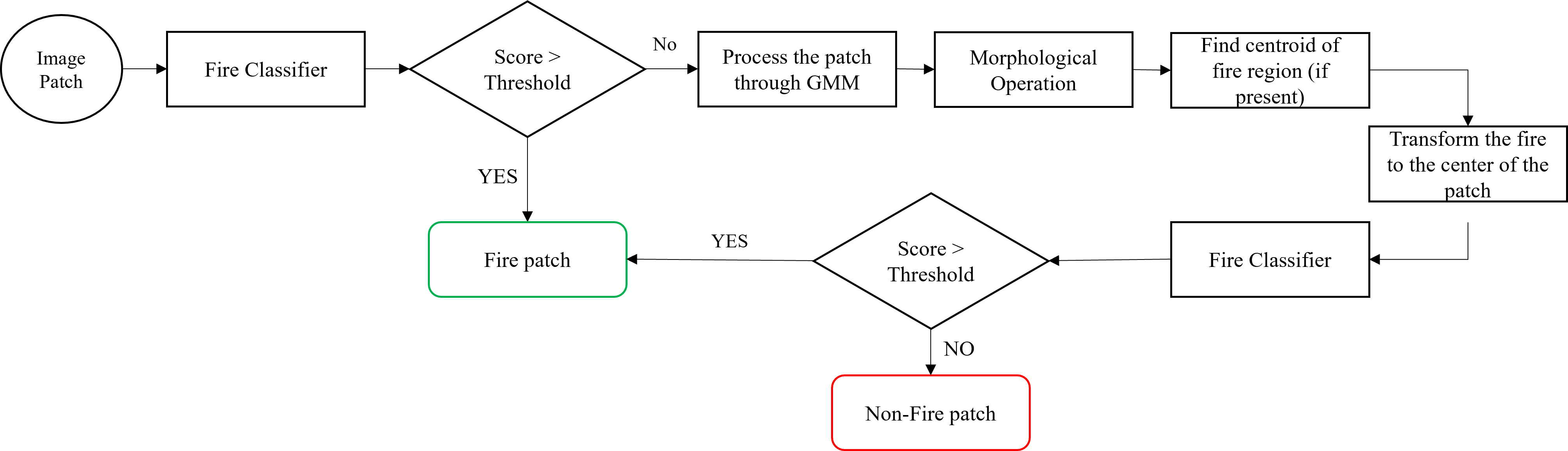
This design maintains real-time performance while improving robustness to flame position and scale.
Results and Insights
- Consistent accuracy improvement across multiple backbones
- Strong gains for corner and edge flame cases
- Minimal computational overhead per frame
- Competitive or superior performance compared to detection-based methods in early-stage fire scenarios
Notes and Lessons Learned
- Fire detection is a spatio-temporal reasoning problem, not purely a classification task
- Classical vision remains valuable when integrated structurally
- Spatial normalization can outperform architectural complexity
- Hybrid pipelines are often preferable for safety-critical, real-time systems
This project directly influenced later work on guided inference, global–local reasoning, and feedback-driven vision systems.